
In the course Scalable Computing at the RUG university, we build again a scalable application - although this time the focus was more on the scalable of the system than setting up the infrastructure around it. In this article more information about the infrastructure and especially docker swarm is presented. The project can be found on Github.
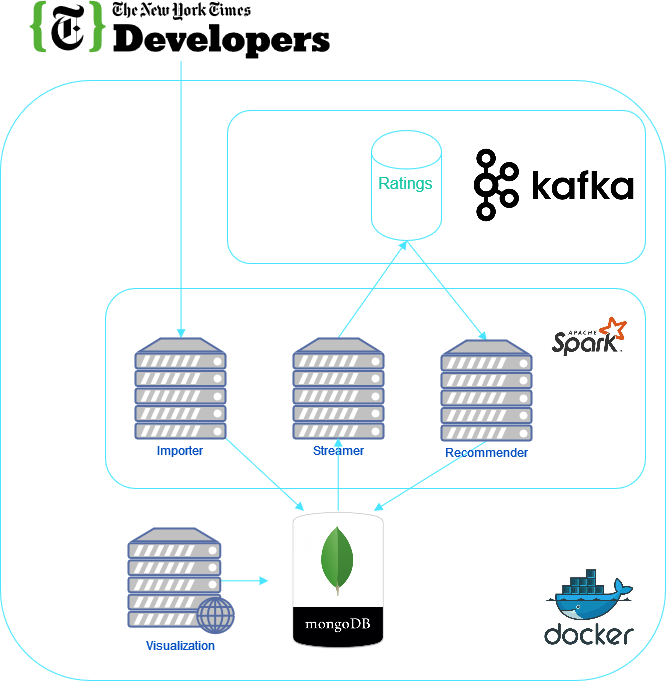
The project is about receiving news articles from an API and then recommending them to the users based on their preferences. In total 9 services are involved in order to provide these functionality:
- MongoDB: Database storage
- Kafka: Allowing for stream processing
- Importer: Loading the data from the NY-Times API and saving them in the database
- Streamer: Creating (random) recommendations for new articles (since we have no real, live users)
- Recommender (batch): Recommending articles to users based on their ratings (from the streamer)
- Recommender (streamer): Recommending articles to users based on the previous calculated recommendation matrix from the batch process
- Visualization: Some basic visualization of the database (also possible generation of random users)
- Spark (master): Apache Spark master node
- Spark (worker): Apache Spark worker node that receives its info from the master node
For a more detailed explanation of the recommendation algorithm, which is essence is the ALS (Alternating Least Squares) method for collaborative filtering, have a look at the report.
All in all, the project is able to recommend articles for users based on its ratings. Setting up the cluster is very easy through the use of docker swarm and it does scale easily. However, we noticed that in a distributed cluster, the performance drops if the network connection is not fast enough a.k.a. the latency is too high.
Kafka and Apache Spark work like a charm and are easy to set up. The difficulty lies in the first steps of programming, especially for Apache Spark since a the Map-Reduce-Paradigm requires a new way of thinking for data processing. Also all dependencies of your program have to be sent to the cluster (manually), which can be easily solved (see our environment variables).